This algorithm cleverly recreates 3D objects from tiny 2D images

With a lifetime of observing the world informing our perceptions, we’re all pretty good at inferring the overall shape of something we only see from the side, or for a brief moment. Computers, however, are just plain bad at it. Fortunately, a clever shortcut created by a Berkeley AI researcher may seriously improve their performance.
It’s useful to be able to see something in 2D and guess accurately the actual volume it takes up — it would help with object tracking in AR and VR, creative workflows, and so on. But it’s hard!
Going up a dimension means you’ve got a lot more data to think about. Take an image that’s a hundred pixels on each side, for a total of 10,000 pixels. An accurate reproduction of it might be a hundred pixels tall as well, making for a total of a million pixels — voxels, actually, now that they’re 3D. And if you want to be even a little more precise, say go up to 128 pixels, you need two million voxels.
What’s in every one of those voxels (i.e. whether it’s “empty” or “full”) has to be calculated by analyzing the original image, and that calculation piles up fast if you want any real fidelity.
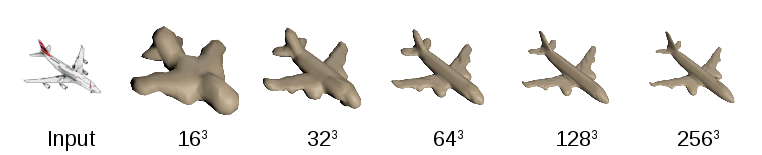
The 2D image at left as rendered with a 16-voxel-cubed volume, 32 cubed, and so on. The quality improves but the computational cost skyrockets.
That’s held back the otherwise highly desirable possibility of extrapolating 3D forms from 2D images. But Christian Häne, at the Berkeley Artificial Intelligence Research lab, figured there had to be a better way. His solution is at once computationally clever and forehead-slappingly simple.
He realized that generally you’re not actually calculating a whole volume of 100x100x100, but only trying to describe the surface of an object. The empty space around it and inside it? Doesn’t matter.
So first his system renders a 3D reconstruction of the 2D image in very low resolution. You can still get a lot from that — for example, that the outer third of the whole volume appears to be empty. Boom, throw all that away.
Next, do a higher-resolution render of the area you kept. Oh, the top and bottom are empty, but the middle is full of pixels, except for a big chunk in the center? Throw out the empty bits, rinse and repeat.
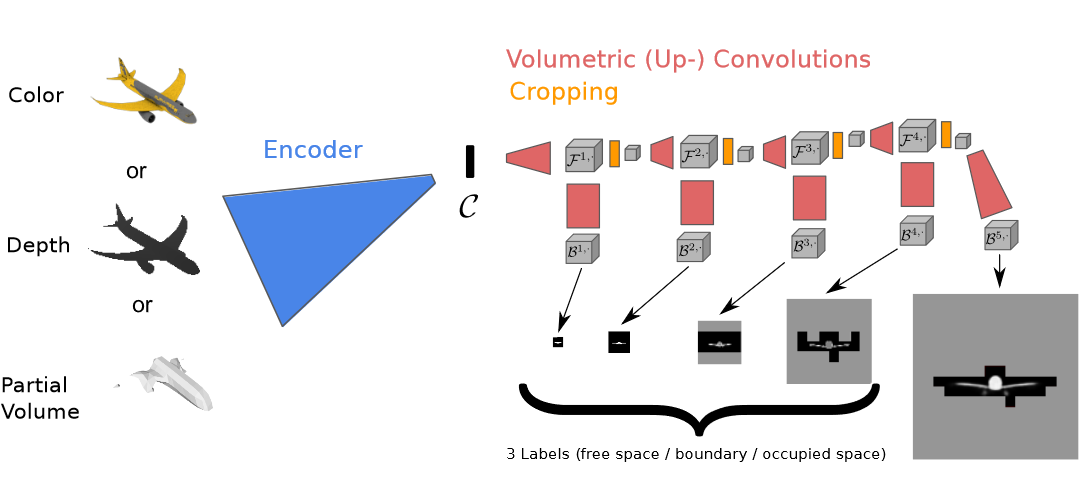 Once you do this a few times, you actually have a 3D volume of high spatial resolution that has taken comparatively little calculation to produce, since it’s only ever calculating parts it knows have meaningful information.
Once you do this a few times, you actually have a 3D volume of high spatial resolution that has taken comparatively little calculation to produce, since it’s only ever calculating parts it knows have meaningful information.
The resulting models were compared with ones generated by more traditional means, and generally they appear to be as good or better, while requiring far less computation to create. You can see more examples in the paper, which you can download from Arxiv here.
It’s far from a complete solution, and humans are still orders of magnitude better at this. But this is a nice workaround that actually mirrors some of the ways our own visual system optimizes itself. Part of the reason we’re so good at what we do is because our brain is so good at throwing away data it has deemed superfluous to successful perception. You don’t notice these shortcuts most of the time, but occasionally they manifest in things like optical illusions.
Making computers see more like humans do sometimes means mimicking the brain’s weaknesses as well as its strengths. This doesn’t go far enough to really be called anthromimetic, but it’s close — and more importantly, it works.
Featured Image: Christian Häne / UC Berkeley